[FILMEET] 100ms를 향한 성능 최적화 여정
24,008ms -> 101ms로! API 99% 성능 개선을 이뤄낸 최적화 과정 이야기
개요
24,008ms → 100ms, 99.5% 성능 개선! 단 2일 만에 API 최적화에 성공한 과정
최근 진행한 프로젝트에서 API의 응답 시간이 24초가 넘는 심각한 성능 이슈가 있었습니다. 백엔드 팀원들과 함께 단 2일 동안 DB 인덱스 튜닝, 캐싱 적용, 커넥션 풀 최적화 등을 통해 평균 응답 시간(TTFB)을 100ms로 단축하는 성과를 이뤄냈습니다.
본 포스팅에서는 실제 성능 최적화 과정과, API 병목을 분석하고 해결한 방법을 상세히 정리했습니다.
서버 성능은 단순히 기술적인 문제가 아니라 사용자 경험과 비즈니스 성과에 직접적인 영향을 미치는 중요한 요소입니다. 따라서 서버 개발자는 지속적인 모니터링과 최적화를 통해 서버 성능을 개선하는 것이 매우 중요하다고 생각합니다.
따라서, API 성능이 사용자 경험과 비즈니스 성과에 어떤 영향을 미치는지 조사해보았습니다.
사용자 이탈률 감소
사용자들은 웹사이트의 로딩 속도에 매우 민감하게 반응합니다. 구글의 연구 결과에 따르면:
- 페이지 로딩 시간이 3초 이상 걸리면 53%의 사용자가 이탈합니다.
- 로딩 시간이 1초에서 3초로 늘어나면 이탈률이 32% 증가합니다.
- 로딩 시간이 1초에서 5초로 늘어나면 이탈률이 90%나 증가합니다.
사용자 경험 개선
빠른 서버 응답 시간은 사용자 만족도를 높이고 긍정적인 브랜드 이미지를 형성하는 데 도움이 됩니다. 사용자의 47%는 웹페이지가 2초 이내에 로드될 것으로 기대합니다.
비즈니스 성과 향상
서버 성능 개선은 직접적인 비즈니스 성과로 이어질 수 있습니다:
- 아마존의 경우, 페이지 로딩 지연이 100ms 증가할 때마다 매출이 1% 감소했습니다.
- 핀터레스트는 로딩 시간을 40% 개선한 결과, 가입자 수와 SEO 트래픽이 15% 증가했습니다.
이러한 생각 때문에 백엔드 팀 회의에서 API 성능 최적화를 고도화 목표로 설정했습니다.
성능 목표 설정
본 프로젝트는 LG U+ 유레카 과정에서 진행되었습니다. 작업을 시작하기에 앞서 U+ 현직 개발자 멘토님께 조언을 구할 수 있는 기회가 있었습니다.
질문 - “U+의 API 성능에 대한 기준이 있나요?”
답변 - “U+에서는 모든 API가 목표를 달성하는 것은 아니지만, 100ms를 목표로 개발하고 있어요”
그래서 저희 백엔드 팀은 달성할 수 있을지 모르겠지만, 목표는 높은 것이 좋다고 생각하여 100ms를 성능 목표로 잡았습니다.
테스트 툴 및 테스트 환경
모니터링 툴 선정
테스트 툴을 선정하는 과정에서 개발 경력 20년의 네이버 출신 멘토님께 조언을 구했습니다.
질문 - “멘토님은 어떤 모니터링 툴을 선호하시나요?”
답변 - “네이버에서는 Pinpoint를 사용하고 있어요. (Pinpoint의 장점을 설명해주셨습니다)”
Pinpoint라는 툴을 멘토님을 통해 처음 알게 되었고, Pinpoint는 네이버에서 개발한 모니터링 오픈소스였고, API 성능 개선을 위해 병목 지점 확인 용도로 사용하기에 어떤 툴이 좋을지 가장 유명한 프로메테우스 + 그라파나 조합과 비교해봤습니다.
| 항목 | Prometheus + Grafana | Pinpoint |
|---|---|---|
| 주요 목적 | 시스템 및 인프라 모니터링 | 애플리케이션 트랜잭션 추적(APM) |
| 트랜잭션 추적 | ❌ (Jaeger, Zipkin 필요) | ⭕ |
| 시각화 | Grafana에서 고급 대시보드 제공 | 기본적인 시각화 (커스터마이징 제한) |
| 확장성 및 유연성 | ⭕ (다양한 Exporter, 커스터마이징 가능) | ❌ (Java/PHP 위주) |
| 설치 및 설정 | 복잡 (Exporter, Grafana 등 설치 필요) | 간단 (에이전트 추가로 바로 사용) |
| 언어 지원 | 다수의 언어 및 서비스 | Java, PHP 중심 |
| 알람 및 경고 시스템 | ⭕ (Alertmanager 활용) | ⭕ (기본 알람 기능) |
결론적으로 Pinpoint가 우리의 목적과 일치했습니다!
🚀 Why?
- Prometheus + Grafana는 시스템 및 인프라 모니터링에 강점이 있지만, API 트랜잭션 추적(APM) 기능이 부족했습니다.
- 반면, Pinpoint는 개별 API 요청의 실행 시간과 병목 구간을 상세히 분석할 수 있었습니다.
- 따라서 “우리는 API 최적화가 목표”였기 때문에, Pinpoint가 최적의 선택이었습니다.
테스트 서버 환경
테스트 서버 환경은 인프라를 담당해준 팀원이 구성해주었기 때문에 팀원의 고민을 요약해서 공유하면 아래와 같습니다!
테스트 환경 설계 요약
테스트 환경 선택지
- AWS에서 모든 테스트 실행
- ✅ 장점: 실제 운영 환경과 동일한 테스트 가능
- ❌ 단점: 비용 증가, 운영 데이터와 혼동 가능
- 로컬에서 Spring 서버 실행 + AWS에 부하 테스트 및 RDS 구성
- ✅ 장점: 비용 절감, 협업 용이
- ❌ 단점: 네트워크 환경 반영 어려움
- 로컬에서 모든 테스트 실행
- ✅ 장점: 비용 없음, 간단한 설정
- ❌ 단점: 운영 환경과 차이 큼, 테스트 데이터 공유 어려움
Pinpoint 배포 선택지
- 로컬에 설치
- ✅ 장점: 비용 없음, 간단한 설정
- ❌ 단점: 협업 어려움, 중앙 집중 데이터 수집 불가
- AWS에 설치
- ✅ 장점: 팀원이 공유할 수 있는 중앙 집중형 모니터링 환경 제공
- ❌ 단점: EC2 및 HBase 사용으로 비용 발생
최종 선택
- AWS에 부하테스트, Pinpoint, 테스트용 RDS 구성
- 각 개발자는 로컬에서 Spring 서버 실행 후 부하 테스트 진행
설정 이유
✅ 비용 효율성
- 로컬에서 Spring 서버 실행 → ECS(Fargate) 비용 절감
- 최소한의 AWS 리소스 활용
✅ 협업 및 중앙 관리
- AWS RDS와 Pinpoint를 통해 모든 개발자가 동일한 환경에서 테스트 가능
- Pinpoint Web을 활용한 실시간 트랜잭션 흐름 및 병목 지점 분석
✅ 테스트 데이터 분리
- 테스트용 RDS를 별도로 구성해 운영 데이터와 철저히 분리
- 테스트 완료 후 데이터 초기화 또는 삭제 가능
✅ 확장 가능성
- 팀 전체의 Spring 서버를 AWS ECS로 이전 가능
- AWS 리소스를 확장해 더 높은 트래픽 테스트 수행 가능
이 설계를 통해 비용을 최소화하면서도 운영 환경과 유사한 테스트 환경을 구성할 수 있었습니다.
테스트 DB 데이터
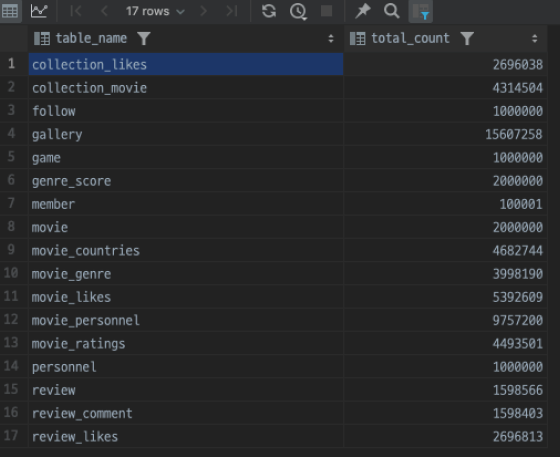
테스트 DB의 16개 테이블에 100만 ~ 1000만 개의 데이터를 넣어서 부하 테스트에 적합한 환경을 만들었습니다.
API 성능 개선 방법
저희 백엔드 팀은 성능 테스트 환경을 완성한 뒤 아래와 같이 API 성능 개선 방법을 정했습니다.
- 부하 테스트 진행 및 개선이 필요한 API 선정 및 담장자 할당
- Pinpoint를 통해 API 병목 지점 분석
- 병목 지점 별 최적화
- Controller, Service
- 코드 리팩토링
- Repository
- SQL을 여러번 실행하여 평균 응답시간 확인
- EXPLAIN, EXPLAIN ANALYZE로 실행 계획 분석
- 쿼리 최적화
- Controller, Service
- 반복
초반 최적화 과정
1차 부하 테스트
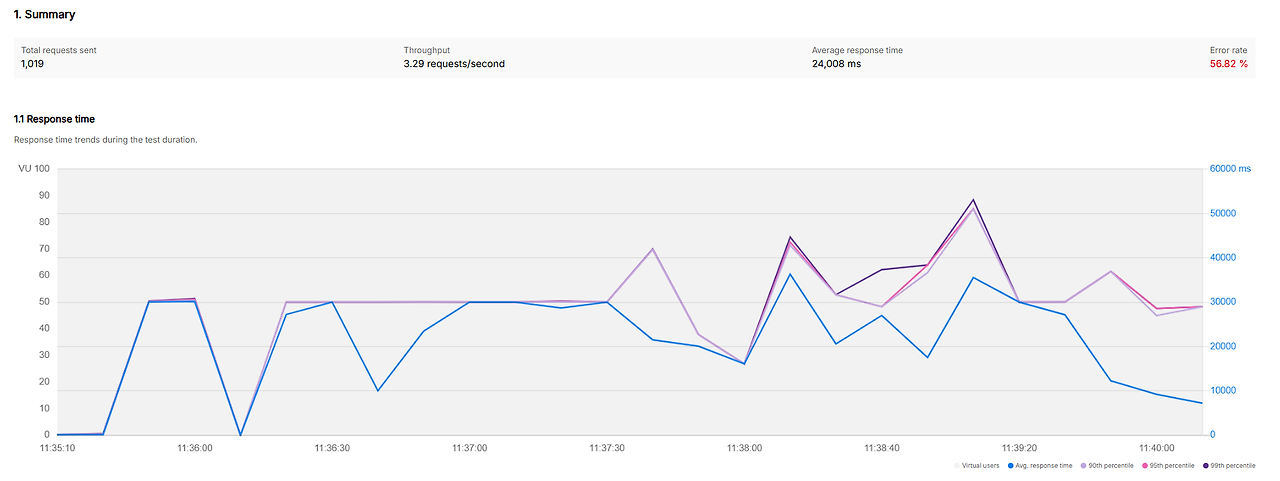 1차 부하 테스트 결과
1차 부하 테스트 결과
| 항목 | 값 |
|---|---|
| 가상 유저 | 100 명 |
| 요청 시간 | 5 분 |
| 커넥션 풀 | 10 |
| 요청 수 | 1,019 |
| 평균 응답 시간 | 24,008 ms |
| 에러율 | 약 56 % |
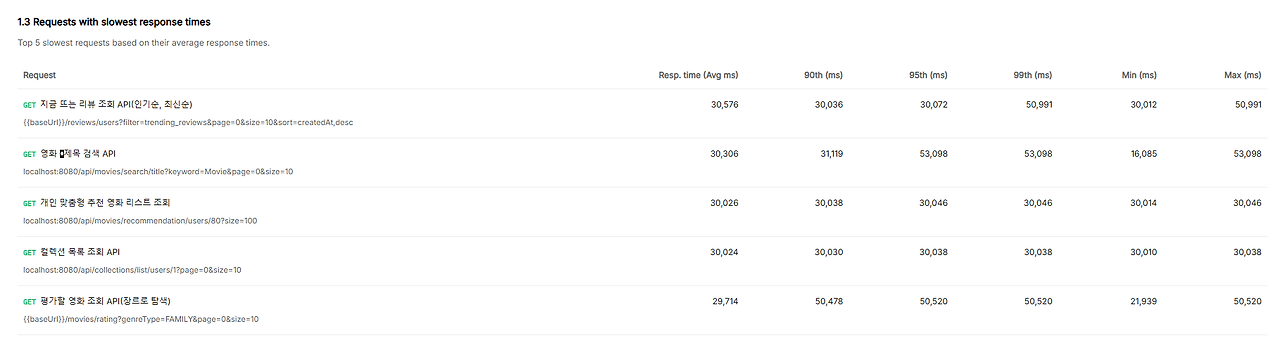 1차 부하 테스트 API Worst 5
1차 부하 테스트 API Worst 5
1차 부하 테스트 결과는 정말 경악스러웠습니다.
특히, Worst 5 API의 평균 응답은 약 30초가 걸렸고 병목으로 인한 Time-out 에러가 너무 많아서 유의미한 부하 테스트 결과라고 할 수 없었습니다.
우선 에러가 없는 성능 테스트 결과를 얻은 이후에 최적화를 진행할 수 있다고 판단되어, Time-out 에러를 제거하기 위해 커넥션 풀을 조정하며 반복해서 부하 테스트를 진행했습니다.
커넥션 풀 조정 및 부하 테스트
| 커넥션 풀 | 평균 응답 시간 | 에러율 |
|---|---|---|
| 10 | 약 24 s | 약 56 % |
| 20 | 약 13 s | 약 66 % |
| 200 | 약 5 s | 0 % |
 커넥션 풀 200개 부하 테스트 결과
커넥션 풀 200개 부하 테스트 결과
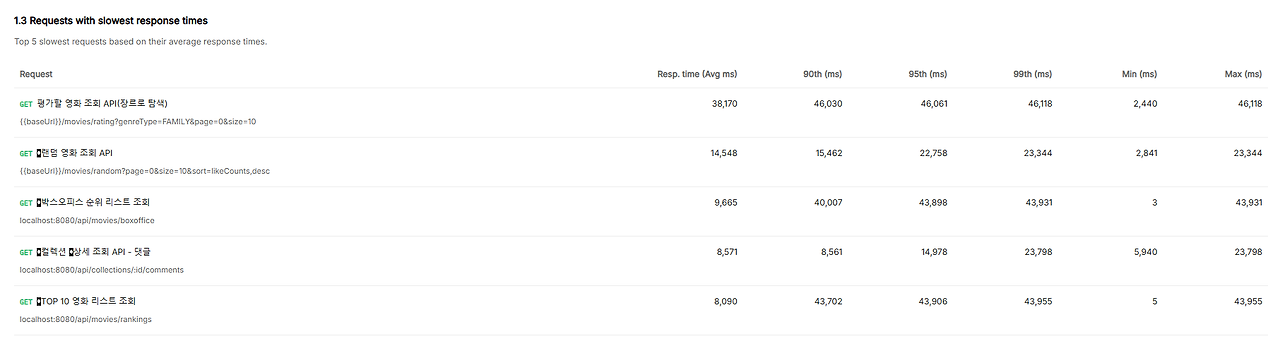 커넥션 풀 200개 Worst 5
커넥션 풀 200개 Worst 5
결론적으로 1차 부하 테스트 대비 아래와 같은 결과가 있었습니다.
| 항목 | 변경 전 | 변경 후 | 변화율 |
|---|---|---|---|
| 커넥션 풀 | 10 | 200 | - |
| 요청 수 | 1,019 | 1,913 | 87.7% 증가 |
| 평균 응답 시간 | 24,008 ms | 5,059 ms | 79.2% 단축 |
| 에러율 | 약 56 % | 0 % | 100% 개선 |
중반 최적화 과정
이제 에러율 0 %으로 만들어서 신뢰할 수 있는 부하 테스트 결과를 얻었기 때문에 본격적으로 개별 API 성능 최적화를 시작했습니다.
위에서 설명한 것과 마찬가지로 Worst API 순서대로 Pinpoint를 통해 API 요청에 대하여 메서드 단위 별로 소요 시간을 분석하여 최적화를 진행했습니다.
지금 뜨는 리뷰 조회 API (복합 인덱스)
영화 개봉 예정일 쿼리 (단일 인덱스)
영화 제목 검색 쿼리 (FULLTEXT INDEX)
개인 맞춤형 추천 영화 리스트 조회 (단일 인덱스)
컬렉션 제목 검색 API(Generated Column, FULLTEXT INDEX, 필요한 인덱스만 Query)
ETC..
다양한 API를 개선했지만 API 대부분의 원인과 최적화 철자는 비슷했기 때문에 예시로 추천 영화 조회 API를 개선하는 과정을 설명드리겠습니다.
병목 지점 분석
중반 최적화 과정은 앞서 설명드린 최적화 단계의 2번 단계부터 시작됩니다.
- 부하 테스트 진행 및 개선이 필요한 API 선정 및 담장자 할당
- Pinpoint를 통해 API 병목 지점 분석
- 병목 지점 별 최적화
- 반복
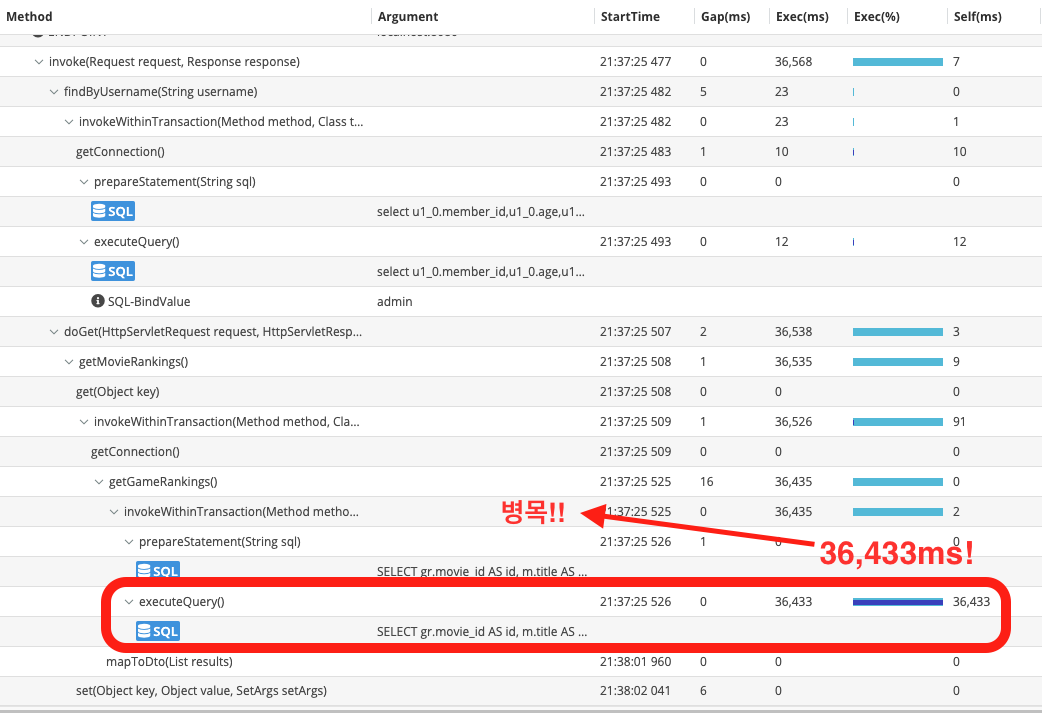
최적화의 모든 과정을 기록하며 진행하지 않아서, 사진 속 API는 추천 영화 조회가 아닙니다!!
위 사진과 같이 Pinpoint에서 Repository 레이어에서 병목이 발생하는 것을 확인할 수 있었습니다.
최적화
실제 SQL 쿼리 실행 시간이 얼마나 걸렸는지 확인하기 위해서 실행 계획을 통해 분석했습니다.
Query Plan이란?
- DBMS가 SQL 쿼리를 처리하기 위해 사용하는 실행 계획으로, 쿼리 실행에 대한 단계를 보여주며 각 단계에서 필요한 리소스와 처리 시간을 단계적으로 보여준다.
Respository에서 실행되는 SQL 문 확인
1
2
3
4
5
6
7
8
9
10
11
12
13
(SELECT *
FROM movie m
WHERE m.like_counts > 0
AND m.is_deleted = false
ORDER BY m.like_counts DESC
LIMIT 1000)
UNION
(SELECT *
FROM movie m
WHERE m.average_rating > 0
AND m.is_deleted = false
ORDER BY m.average_rating DESC
LIMIT 1000);
Query Plan

1
2
3
4
5
6
7
8
9
10
-> Table scan on <union temporary> (cost=438405..438433 rows=2000) (actual time=32713..32714 rows=1999 loops=1)
-> Union materialize with deduplication (cost=438405..438405 rows=2000) (actual time=32713..32713 rows=1999 loops=1)
-> Limit: 1000 row(s) (cost=219103 rows=1000) (actual time=16839..16839 rows=1000 loops=1)
-> Sort: m.like_counts DESC, limit input to 1000 row(s) per chunk (cost=219103 rows=1.98e+6) (actual time=16838..16838 rows=1000 loops=1)
-> Filter: ((m.is_deleted = false) and (m.like_counts > 0)) (cost=219103 rows=1.98e+6) (actual time=3.61..14490 rows=2e+6 loops=1)
-> Table scan on m (cost=219103 rows=1.98e+6) (actual time=3.6..14192 rows=2e+6 loops=1)
-> Limit: 1000 row(s) (cost=219103 rows=1000) (actual time=15844..15844 rows=1000 loops=1)
-> Sort: m.average_rating DESC, limit input to 1000 row(s) per chunk (cost=219103 rows=1.98e+6) (actual time=15844..15844 rows=1000 loops=1)
-> Filter: ((m.is_deleted = false) and (m.average_rating > 0.00)) (cost=219103 rows=1.98e+6) (actual time=17.3..13084 rows=2e+6 loops=1)
-> Table scan on m (cost=219103 rows=1.98e+6) (actual time=14.1..12707 rows=2e+6 loops=1)
최적화
type이 ALL로 표시되어 있어, 테이블 전체 스캔(Full Table Scan)이 발생하고 있음을 확인할 수 있습니다. possible_keys 및 key 항목이 모두 null로 표시되어, 인덱스를 전혀 사용하지 않고 쿼리가 실행되고 있음을 확인할 수 있습니다. 테이블 전체 스캔을 하다 보니 2백만 건(2e+6)의 데이터를 조회하는 데 14~17초가 소요되고 있는 상황입니다.
가장 큰 문제는 Full Table Scan이 발생하는 것이었습니다. 이를 해결하기 위해 인덱스를 생성하여 쿼리가 인덱스를 타도록 수정했습니다.
특히, 조회 시 like_counts와 average_rating을 기준으로 정렬하는 부분이 병목의 원인이었기 때문에, 이 두 컬럼을 중심으로 인덱스를 추가하여 쿼리 성능을 개선했습니다.
1
2
CREATE INDEX idx_movie_like_counts ON movie (like_counts DESC);
CREATE INDEX idx_movie_average_rating ON movie (average_rating DESC);
인덱스 추가 후
최적화 결과

1
2
3
4
5
6
7
8
-> Table scan on <union temporary> (cost=451396..451424 rows=2000) (actual time=26.1..26.5 rows=1997 loops=1)
-> Union materialize with deduplication (cost=451396..451396 rows=2000) (actual time=26.1..26.1 rows=1997 loops=1)
-> Limit: 1000 row(s) (cost=225598 rows=1000) (actual time=0.0621..7.07 rows=1000 loops=1)
-> Filter: (m.is_deleted = false) (cost=225598 rows=494878) (actual time=0.0614..7 rows=1000 loops=1)
-> Index range scan on m using idx_movie_like_counts over (like_counts < 0), with index condition: (m.like_counts > 0) (cost=225598 rows=989755) (actual time=0.0595..6.84 rows=1000 loops=1)
-> Limit: 1000 row(s) (cost=225598 rows=1000) (actual time=0.0312..12.6 rows=1000 loops=1)
-> Filter: (m.is_deleted = false) (cost=225598 rows=494878) (actual time=0.0307..12.5 rows=1000 loops=1)
-> Index range scan on m using idx_movie_average_rating over (average_rating < 0.00), with index condition: (m.average_rating > 0.00) (cost=225598 rows=989755) (actual time=0.0298..12.4 rows=1000 loops=1)
세부 지표 비교
| 항목 | 기존 실행 계획 | 인덱스 적용 후 실행 계획 |
|---|---|---|
| 쿼리 실행 시간 | 32,713 ms | 26.5 ms |
| 스캔 방식 | Table Scan | Index Range Scan |
| 스캔한 수 | 2,000,000 rows | 1,000 rows (per scan) |
쿼리 실행 시간이 32.7초에서 26.5ms초로 단축되어 99.92%의 성능 개선이 이루어졌습니다.
이와 같은 최적화 접근 방식은 추천 영화 조회 API뿐만 아니라, 다양한 API에서도 적용되었습니다. 각 API의 특성에 맞는 인덱스를 설계하여 최적화를 진행했으며, 불필요한 Table Scan을 제거하고 WHERE 조건과 정렬 연산을 고려한 인덱스 최적화를 통해 전반적인 성능을 향상시켰습니다.
이를 통해 API별로 최적의 검색 전략을 적용함으로써 실질적인 성능 개선을 이루었습니다.
특히, 아래와 같은 주요 최적화 효과를 확인할 수 있었습니다:
- 불필요한 Table Scan 제거:
- 기존에는 Table Scan이 발생하여 모든 데이터를 조회해야 했으나, 인덱스 적용 후 Index Range Scan으로 변환되어 조회 범위가 최적화됨.
- 필터링 효율 향상:
- WHERE 조건에 맞는 인덱스를 설계하여 불필요한 레코드 조회를 최소화하고, is_deleted = false 같은 자주 사용되는 조건도 인덱스를 활용하여 최적화.
- 정렬 속도 개선:
- ORDER BY like_counts DESC, ORDER BY average_rating DESC와 같은 정렬 연산에서 Descending Index를 적용하여 정렬 속도를 크게 단축.
- Full-Text Index 활용:
- 검색 기능을 담당하는 API에서는 LIKE 연산 대신 Full-Text Index를 사용하여 문장 검색 성능을 크게 향상.
- 복합 인덱스(Composite Index) 적용:
- 여러 조건이 결합된 조회 (WHERE like_counts > 10 AND average_rating > 4.0)에서는 복합 인덱스를 활용하여 연속적인 검색 속도를 개선.
중반 최적화 결과

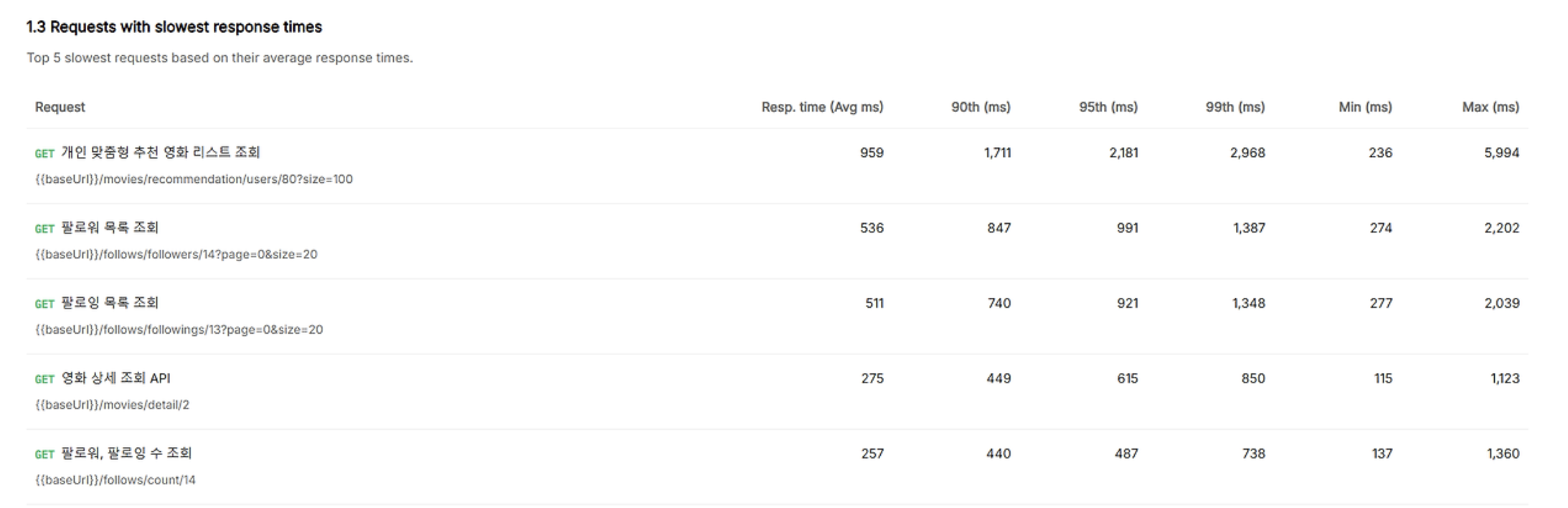
| 항목 | 변경 전 | 변경 후 | 변화율 |
|---|---|---|---|
| 총 요청 수 | 1,019 | 102,855 | 100배 증가 |
| 평균 응답 시간 | 24,000 ms | 160 ms | 99.3% 단축 |
| 에러율 | 56% | 0% | 100% 개선 |
마지막 최적화 과정
초반 부하 테스트와 비교 했을 때 엄청난 성과를 이루었지만, 목표인 100ms를 아직 달성하지는 못했기 때문에 마지막 최적화를 진행했습니다.
캐시 적용
개인 맞춤형 추천 영화 리스트 조회할 때는 인기 TOP 10 영화를 제외한 영화들 중에서 선택을 하는데, 매번 TOP10 영화를 계산하는 과정이 굉장히 비효율적이었습니다.
그래서 TOP10 영화를 조회하는 API에서 Redis에 캐시를 하고, 개인 맞춤형 추천 영화 리스트 조회 API에서는 캐시 한 TOP10 영화를 조회해서 해당 영화들을 제외하고 나머지 로직을 진행했습니다.
커넥션 풀 최적화
DB 커넥션 풀은 데이터베이스와 애플리케이션 간의 연결을 효율적으로 관리하는 중요한 구성 요소입니다. 하지만 테스트 과정에서 Time-out 에러를 피하기 위해 커넥션 풀을 단순히 증가시키는 방식을 적용했으며, 이는 최선의 해결책이 아님을 인지하고 있었습니다.
커넥션 풀 크기를 너무 작게 설정하면 요청이 대기 상태에 빠질 위험이 있고, 반대로 너무 크게 설정하면 메모리와 리소스가 불필요하게 낭비될 수 있습니다. 따라서 단순히 커넥션 풀 크기를 늘리는 것이 아닌, 적절한 설정과 최적화가 필요하다는 점을 확인했습니다.
최적의 커넥션 풀 계산 공식
최적의 DB 커넥션 풀을 찾기 위해서 다양한 자료를 찾아보고, 여러 곳의 벤치마크 결과를 통해 검증된 공식은 아래와 같습니다.
\[\text{활성 커넥션 수} = (4 \times 2) + 2 = 10\]
스핀들이란, HDD의 물리적 플래터(데이터 저장 원반)를 움직이는 축을 의미하므로 유효 스핀들 수는 HDD에서 동시에 읽고 쓸 수 있는 독립된 경로를 의미합니다.
위 공식은 하이퍼스레딩(물리적 코어를 두 개의 논리적 스레드로 나누어 동작하게 하는 기능)이 적용되어 있더라도
HT스레드(논리적 스레드, 여기선 물리적 코어보다 많음)를 제외한 실제 물리적 코어 수만을 계산합니다.
그래서 위 공식을 다시 정리하자면,
- CPU 코어 수: 물리적 CPU 코어 수(하이퍼스레딩 무시).
- X 2: CPU 하나가 I/O 대기 시간을 줄이고 효율적으로 스레드를 처리할 수 있도록 두 개의 연결을 할당
- 유효 스핀들 수: 하드 디스크에서 동시에 데이터를 읽고 쓸 수 있는 경로 수
- SSD를 사용하면 유효 스핀들 수 = 0으로 계산
예제 1
4 코어 i7 CPU와 HDD
- 물리적 CPU 코어: 4개
- 유효 스핀들 수: 1 (하드 디스크가 1개)
활성 커넥션 수 = (4 X 2) + 1 = 9의 커넥션이 최적입니다.
예제 2
4코어 i7 서버 + SSD:
활성 커넥션 수 = (4 X 2) = 8개의 커넥션이 최적입니다.
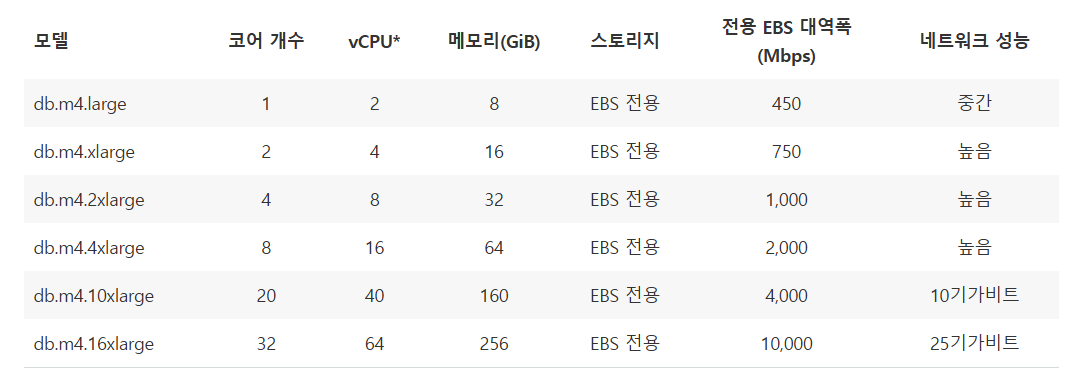
그래서 저희가 사용한 RDS는 M4.2xlarge로, 코어가 4이기 때문에 (4 X 2) = 8 (RDS는 대부분 SSD 사용) 200개에서 8개의 커넥션 풀로 설정하고 마지막 부하테스트를 진행했습니다.
최종 결과

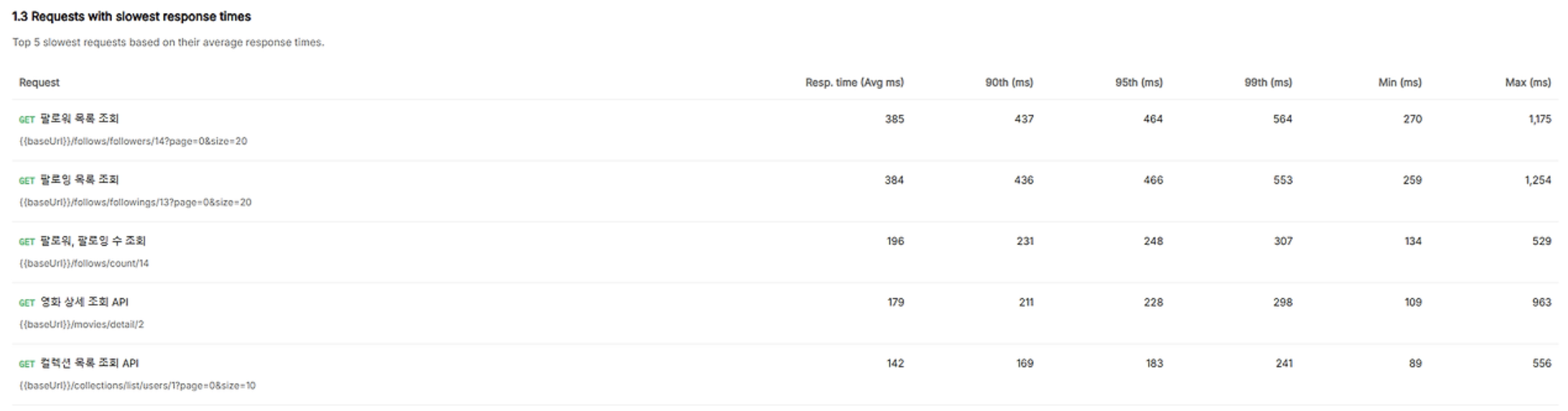
| 항목 | 변경 전 | 변경 후 | 변화율 |
|---|---|---|---|
| 총 요청 수 | 1,019 | 131,734 | 📈 129배 증가 |
| 평균 응답 시간 | 24,000 ms | 100 ms | ⏳ 99.58% 단축 |
| 에러율 | 56% | 0% | ✅ 100% 개선 |
마무리 - 배운 점과 느낀 점
📌 결론: “단순한 코드 최적화가 아니라, 시스템 전체를 고려하는 사고방식이 필요하다”
이번 성능 최적화 과정에서 가장 큰 배움은 “단순히 코드를 최적화하는 것이 아니라, 시스템 전체를 고려한 전략적인 접근이 필요하다”는 점이었습니다.
✅ “개선해야 할 문제를 정확히 분석하고, 적절한 솔루션을 적용하는 과정”이 성능 최적화의 핵심이었습니다.
✅ 데이터 기반으로 접근하고, 효과를 수치로 측정하면서 점진적으로 개선하는 것이 중요했습니다.
✅ 한 번의 최적화로 끝나는 것이 아니라, 지속적인 모니터링과 관리가 필요하다는 점을 실감했습니다.
마지막으로…
최적화 여정에서 한 몸처럼 2일이라는 짧은 기간 동안 불가능할 것 같았던 목표를 함께 달성한 우리 백엔드 팀원들 너무 고맙습니다. 🚀
인덱스 최적화 전략, 커넥션 풀 설정 방법, 캐싱 전략 등을 서로 공유하면서 팀 전체의 역량이 함께 성장할 수 있었습니다.
샤라웃 투 마 보이즈… 앤 멘토님들…
긴 글 읽어주셔서 감사합니다!!
참고
https://an-jjin.tistory.com/229